マルチモーダルAIの防災減災分野への展開に向けた考察
- 著者
- 矢野 良輔 東京海上ディーアール 企業財産本部 上級主任研究員 博士(理学)
- 佐藤 一郎 東京海上ディーアール 企業財産本部 本部長 博士(工学)
- 監修
- 今村 文彦 東北大学災害科学国際研究所 教授
監修者コメント
自然災害は激甚化・複雑化の傾向にあり、繰り返し甚大な被害をもたらしている。ハザードに関しては予測技術や周期性の特定が進展しているものの、実際の被害規模は地域の曝露性や社会的な脆弱性に依存するため、事前防災等の対策は未だ十分とは言い難い状況にある。 防災対策や機能の向上には、1) データに基づくメカニズム解明、2) 予測・評価、3) リスク軽減策の実施、という3つの柱の強化が不可欠である。しかし、1) については古文書等を含むテキストデータや映像・画像データが豊富に存在するにもかかわらず、統合的な利活用が進んでいない。また、2) および 3) についても、過去の記録の断片化が障壁となり、将来予測や具体的対策への接続が不十分である。 これらの課題を解決する有力なアプローチとして期待されるのが「マルチモーダルAI」である。本稿では、その可能性と効果、および実用化に向けた課題を整理している。マルチモーダルAIは、今後の防災分野における基幹技術となることが期待される。
 今村文彦
今村文彦
東北大学災害科学国際研究所教授・副学長
要約
- 課題認識:
- 災害は空間的・時間的に不均質で、過去事例の一般化や知識の再利用が難しい。一方、生成AIの進展により、事例に基づく知識構造化や検索再利用性の向上が現実的になりつつある。
- 取組試行:
- マルチモーダル技術および生成AIを活用し、地域特化型災害ナレッジベースとして、画像と文書を統合して意味情報として蓄積し、検索・再利用性を高度化する取組を試行した。
- 意見交換:
- 東北大学災害科学国際研究所との意見交換を実施し、「認知」「周知」「対応」の各フェーズでのマルチモーダルAIの利活用の可能性と課題について議論を行った。
- 主要成果:
- オープンソースの大規模言語モデル(LLM)やマルチモーダル技術の活用により、文書だけでなく画像を含めた過去の災害情報の再利用性を高められる可能性があることを示した。
-
目次
1. はじめに
1.1 激甚化する災害と国の防災DX戦略
日本列島は、地理的条件や気象条件から台風・豪雨・豪雪・洪水・土砂災害・地震・津波・火山噴火などが発生しやすい環境にある。そして、国土の狭さもあり国民生活や社会経済活動の基盤となる生活圏・都市圏にその影響が災害となって顕在化しやすく、課題先進国ともいわれる。
こうした災害をたびたび乗り越えてきたことが日本社会の強みである。しかし、災害発生は空間的・時間的に不均質であり、過去の経験知を次の災害に活かすまでの期間が長い。そのため、その間の経験知の蓄積・伝承が困難であるという課題が存在する。特に、建築基準など行政が所管する領域では各種基準が高度化する一方で、企業や住民の行動に直結する災害対応や事前の備えといった、いわゆるソフト防災分野では更なる高度化の余地が残されている。
このような背景の中で、災害対応や備えの高度化にデジタル化やDXが有効であることは論を俟たない。政府はデジタル社会の実現に向けた重点計画の中で、防災分野を重点的に取り組むべき分野と位置付け、新総合防災情報システム(SOBO-WEB)[1]を中核とする防災デジタルプラットフォームの構築を進めている。また、デジタル庁は、防災分野を「準公共分野」に位置づけ、内閣府防災などの関係省庁や地方自治体・民間企業等と連携を図りつつ、防災に係るアプリ開発やデータ連携促進の取組を進めている。そして、令和6年能登半島地震の経験を踏まえて、2025年8月には、防災DX官民共創協議会と協働して災害派遣デジタル支援チーム(D-CERT)を創設することが発表され[2]、2025年9月には、D-CERTの事務局を担う組織として、一般社団法人デジタルコーディネーションセンター(DIT/CC)が設立された。研究開発の分野でも、内閣府SIP第3期「スマート防災ネットワークの構築」において、生成AIを活用した訓練状況付与の自動生成など、災害対応の高度化に向けた研究開発が推進されている[3]。
1.2 災害ナレッジの再利用性に係る課題
近年普及した汎用大規模言語モデル(LLM)は、要約や情報整理、一定の推論を高い水準で実現する一方、地域・組織固有の前提や文脈を踏まえた解釈を安定して行うことは難しく、根拠提示や監査可能性の面でも課題が残る。このような背景に基づき、領域特化型LLMの研究が各分野で進められている。例えば、医療分野では、電子カルテ等により日常的にデータが蓄積され、用語・文書形式の標準化も進んでおり、継続事前学習による日本語医療LLMの研究も進展している[4]。
一方、災害分野は発生が時間・空間的に不均質で、記録も多源・非定型(画像、報告書、SNS等)となり、医療ほど稠密かつ継続的なデータ整備が進みにくい。国立国会図書館による「ひなぎく」[5]や各大学の災害アーカイブ[6]など、貴重な記録は存在するものの、地域ごとの教訓や被害状況を意思決定に耐える形で横断参照できる仕組みは十分ではない。さらに個人情報を含む場合も多く、取扱いにはプライバシー・セキュリティ上の制約が伴う。
1.3 マルチモーダルAIの活用可能性
前節を踏まえると、災害分野の知識再利用の観点では、領域特化モデルをゼロから構築するよりも、既存記録を出典付きで検索・参照し、必要な文脈を保ったまま再利用する枠組みが重要となると考えられる。その際、画像とテキストを対象とした知識の構造化と再利用性を高めるアプローチの鍵となるのが、検索拡張生成(RAG: Retrieval-Augmented Generation)[7]とマルチモーダル技術の組み合わせである。
RAGは、LLMが持つ汎用的な知識に加えて、外部のデータベースや文書から必要な情報を検索し、それを基に応答を生成する技術である。具体的には、ユーザーの質問に対して関連する過去の文書や記録を検索し、その内容をLLMに与えることで、より正確で文脈に即した回答を生成できる。災害対応の文脈では、特定地域の過去の被害記録や対応マニュアルなど、組織固有のナレッジベースを参照しながら、状況に応じた適切な情報提供が可能となる。このように、RAGは領域特化した知識を効果的に活用するための重要な技術基盤となっている。
一方、災害情報は文書だけでなく、現場写真や衛星画像など視覚情報も重要な役割を果たす。ここで活用されるのが画像質問応答(VQA: Visual Question Answering)をはじめとするマルチモーダル技術である。VQAとは、画像とテキストの質問を同時に入力として受け取り、画像の内容に基づいて質問に答えるAI技術であり、最近のLLMの発展により、より高度な画像理解と自然な言語での応答が可能となっている。例えば、被災地の写真に対して「この建物の損傷度は?」と問いかけると、画像を解析して被害状況を説明できる。さらに、画像キャプション生成技術により、災害現場の写真や衛星画像に自動的に意味付けを行い、テキスト情報として整理することも可能である。
RAGとVQAに代表されるマルチモーダルAIの活用により、過去の災害アーカイブ情報を生成AI活用の観点で再利用し、従来は対応が難しかった固有の情報や文脈を踏まえた事前の備えや発災時対応の高度化が期待される。テキストと画像の両方から知識を抽出・統合することで、より包括的で実践的な災害対応支援が実現できる可能性がある。
1.4 本稿の構成
本稿は、以上の課題認識を背景に、マルチモーダルAIの災害分野への適用可能性を探るために実施した一連の取組について報告するものである。
2022年にChatGPTが登場し生成AIの活用が注目される中、著者らは2023年初頭からマルチモーダルAIの災害分野での活用可能性を探るための情報収集を開始した。並行して、セキュリティやプライバシー保護等の課題に対応するため、外部APIに依存しないオンプレミス環境でのマルチモーダルAI実行基盤を構築し、様々なトライアルを実施した。
その後、現在に至るまで、OpenAI、Google、Anthropicといったテック企業による競争は激化し、より高機能な生成AIが次々と市場投入されている。本稿で紹介するトライアルで用いた技術の一部はすでに古くなっているものもある。しかし、本稿の目的は最新技術の追跡そのものではない。技術の進化を前提としつつも、災害分野における生成AI・マルチモーダルAIの利活用にフォーカスし、具体的なトライアルを通じてその可能性と課題を明らかにすることを目的としている。
さらに、より広範な視点からの考察を得るため、2024年7月以降、東北大学災害科学国際研究所の各分野の専門家との意見交換を実施した。これにより、技術的側面だけでなく、災害科学や防災実務の観点から、マルチモーダルAIの活用可能性と実装上の課題について多角的な考察を試みた。
本稿の構成は以下の通りである。第2章では研究背景と関連動向を概観し、第3章では地域特化型災害ナレッジベースの利活用可能性について具体的なトライアル結果を示す。第4章では、東北大学災害科学国際研究所の専門家との意見交換から得られた知見を整理し、第5章では今後の研究の方向性と展望について論じる。
2. 既往研究の概観
2.1 災害分野でのLLM活用に関する調査
著者らの既往報告[8]で述べた通り、2022年のChatGPT登場以降、防災分野への生成AIの適用に関する研究は爆発的に増加している。Z. Lei, et al. [9]は、2025年に発表した包括的なサーベイにおいて、防災分野におけるLLM活用研究を「減災 (Mitigation)」「準備 (Preparedness)」「対応 (Response)」「復旧 (Recovery)」の災害サイクルフェーズ別、および「エンコーダ型」「デコーダ型」「マルチモーダル型」のアーキテクチャ別に分類し、体系化を行った。
図1は、Z. Lei, et al.の包括的サーベイで調査対象とした141本の論文に対してフェーズ別×アーキテクチャ別にクロス集計を行ったものであり、各セルには全体に対する割合と()内に実数、主なAIのユースケースについて記載している。
![Leiら[9]の防災LLM活用事例(141件)分布図。縦軸は災害フェーズ、横軸はモデル型。画像とテキストを扱う「マルチモーダル型」は全体の約2割を占め、特に復旧期での状況分類や被害推定・説明生成(17.0%)への活用が目立つ。図全体としては復旧期への集中(74.5%)も強調されている。](/thinktank/ai_and_disaster_prevention/report_202601/images/img-report_202601-02-sp.jpg) 図1 防災分野におけるLLM活用の体系と研究事例の分布
図1 防災分野におけるLLM活用の体系と研究事例の分布
Lei et al.(2025)[9]に基づき著者が作成 ()内は実数。N=141
図1における重要な示唆は以下の2点である。
- 1. 「対応 (Response)」フェーズへの研究集中
- 既存研究の約75%(74.5%、105件)が、発災直後の「対応」フェーズに集中している。SNSからの被害情報抽出や緊急性の分類、被害状況の把握といったタスクが主流であり、平時の「減災・準備」や長期的な「復旧」に関する生成AI活用は、未だ開拓の余地が大きい領域として残されている。
- 2. マルチモーダル技術の将来性
- 多くの研究はBERTやGPTを用いたテキスト処理(分類・抽出・生成)に留まっている。エンコーダ型(BERT等)とデコーダ型(GPT等)で約8割を占める結果となっている。一方、マルチモーダル型AIの活用は全体の2割強に留まり、特に「準備」フェーズでの活用事例は極めて少ない。
また、全体の調査対象となった多くの研究が検証段階であり、実務とのギャップ解消のために「災害特有のデータセットの不足」「計算効率の課題」「ハルシネーション(事実に基づかない出力)への対処」といった課題への対処が重要であるとしている。そして、RAGを用いて外部の知識ベースと統合することや、領域特化型の学習を行うことで、ハルシネーション低減の可能性があることが指摘されている。
生成AIは、従来個別の専門領域ごとに蓄積されてきた知見を横断的に統合し、人間には処理困難な大量の情報を要約・分析して提供することが可能である。特にマルチモーダル技術と組み合わせることで、テキストと画像を統合して被災状況を総合的に把握できる潜在性を持つ。また、専門家だけが有していた高度な知識や過去の教訓をAIが形式知化して共有することで、専門知の民主化にも寄与しうると考えられる。
2.2 マルチモーダルAI活用の可能性
前節を踏まえると、「平時のデータも含めた全フェーズ」において「画像を含むマルチモーダル情報」を如何に活用するか、においては研究の余地が残されているといえる。とくに、災害情報は文章だけでなく写真、図表、地図など多様な形態で個別に蓄積されており、それらのナレッジを集約して「地域特化型災害ナレッジベース」としてAI-Readyな再利用可能な知識として整理することは、ソフト防災の高度化に資するものと考えられる。
マルチモーダルAI技術の一つであるVQAは、LLMの登場以前から研究がなされていた技術である。VQAは、画像とそれに関する自然言語の質問を入力として受け取り、画像内容に基づいた回答を生成するタスクであり、画像認識と自然言語処理の両方の能力を必要とする。
VQAは一般に、CNN(畳み込みニューラルネットワーク)やViT(Vision Transformer)などの視覚エンコーダと、質問文を処理する言語モデル(テキストエンコーダ/デコーダ)および両者を結合するマルチモーダル融合層を組み合わせたアーキテクチャで実現される。
視覚と言語の表現を整合させる事前学習モデルとして、CLIP(Contrastive Language-Image Pre-training)[10]、BLIP(Bootstrapping Language-Image Pre-training)[11]、が提案され、近年はLLMと視覚エンコーダを接続した視覚対話モデル(例:LlaVA(Large Language and Vision Assistant)[12]、OpenFlamingo[13])へと発展している。さらに、OpenAIのGPT-4 with vision(GPT-4V)により画像入力に対応した汎用LLMの利用が進み、追加学習なし(Zero-shot)でのVQA適用が現実的となった。その後、視覚認識を含むマルチモーダル機能を統合したGPT-5の登場により、より汎用的な応用が進んでいる。
防災分野における具体的事例としては、空撮画像に注目したRescueNetデータセットを活用した取組[14]や、市川・矢野による取組[15]が挙げられる。RescueNet-VQA[14]では約4,300枚の被災地ドローン画像に対し10万件のQAペアがアノテーションされており、各画像は建物状態や道路状態、被害程度などのタイプ別の質問に関連付けられている。市川・矢野[15]はマルチモーダルモデルOpenFlamingoを災害画像データで微調整し、生成キャプションと人手タイトルのBERT埋め込みコサイン類似度で性能評価を行っている。
次章では、既報の内容[16]も含め、画像エンコーダとオンプレミス環境に構築したオープンソースLLMを組み合わせることで、VQAのプロセスや精度を確認・理解する試行した内容を紹介する。具体的には、CLIP、BLIP、LlaVAを用いたVQAシステムを構築し、地域特化型災害ナレッジベースとの統合可能性を検証する。
3. 地域特化型災害ナレッジベースの構築と検証
3.1 システム設計とアーキテクチャ
前章で概観した技術動向を踏まえ、本章では地域特化型災害ナレッジベースの具体的な実装と検証結果を報告する。
本稿の目的は、散在する災害情報を「テキスト+画像+位置情報」として統合し、RAGとマルチモーダルAIを組み合わせることで、利用者の多様なニーズに応答可能な検索基盤のプロトタイプを構築することである。
3.1.1 全体アーキテクチャ
プロトタイプシステムを図2に示す。
大きく、以下の「データ収集・構造化」「マルチモーダル処理」「検索・提示」に分類される。
- データ収集・構造化層
- Webサイトから災害情報をOpenAIのChatGPT deep research (以下、deep research)により自動収集し、災害サイクルの各フェーズに対応する8項目(災害概要、被害状況、避難状況、初動対応、長期復興計画、災害医療・福祉支援、教訓・減災対策、今後の課題と提言)で構造化する。(図2のData SourceのWeb、災害記録誌(PDF))
- マルチモーダル処理層
- 災害アーカイブ画像に対してVQAを適用し、画像内容をテキスト化(キャプション生成)するとともに、位置情報や災害種別等のメタデータを付与する(図2のData Sourceの「画像+テキスト」)
- 検索・提示層
- 構造化されたテキストとキャプション付き画像をベクトルデータベース(VectorDB)に格納し、RAGとLLMを組み合わせたユーザーインターフェース(UI)を通じて、自然言語による検索、類似画像の抽出、ハザードマップ上での可視化を実現する。(図2の災害ナレッジベース、RAG)

この設計により、従来は個別に管理されていた文書情報と画像情報を統合的に扱い、地域固有の災害知識を効率的に参照可能とする。
3.1.2 実装環境
VQAモジュールの応答や挙動を確認する目的で、オープンソースを実装しやすいオンプレミス環境での実装を基本とした。また、今回の試行においては公開情報の扱いを中心とするが、将来的に機密性の高い情報を扱う場合にも、外部APIに依存しないオンプレミス環境が必要になることも想定される。
オンプレミスでの主要な実装環境は以下の通りである。なお、()内の数字は、モデル規模の目安としてのパラメータ数(B=10^9)であり、一部モデルはバックエンドLLM側の規模を示す。
- VQAモデル: CLIP (0.428B)/BLIP ( 0.129B)/LlaVA (7B)
- LLM: Llama2 (7B)
- RAGフレームワーク: LangChain
- 実行環境: NVIDIA RTX A6000 (CUDAコア: 10,752ユニット、VRAM: 48GB GDDR6)
比較検証のため、商用マルチモーダルモデルとしてGPT-5も使用した。オンプレミスモデルは無償利用可能だが、GPUメモリ制約によりパラメータ数は7B~13B程度に限定される。一方、商用モデルは高精度だが従量課金が発生する。
3.2 データ収集と構造化の自動化
3.2.1 deep researchによる自治体情報の構造化
従来、地域特化型の災害情報を収集するには、Webスクレイピングによる情報抽出と人手による内容の選別・整理が必要であり、多大な時間と労力を要した。しかし、deep researchの登場により、あらかじめ指定した項目に沿って必要な情報のみをWeb上から自動収集することが可能となった。
本稿では、東日本大震災を対象とし、全国1,747市区町村について以下の8項目で情報を構造化した。
- 災害概要: 発災日時、震度、津波高等の基本情報
- 被害状況: 死者・行方不明者数、建物被害、インフラ損壊
- 避難状況: 避難所数、避難者数、仮設住宅整備状況
- 初動対応: 災害対策本部の設置、救助活動、支援体制
- 長期復興計画: 復興計画の策定時期、主要施策、整備状況
- 災害医療・福祉支援: 医療機関の被災状況、医療支援体制
- 教訓・減災対策: ハザードマップ整備、防災教育、伝承活動
- 今後の課題と提言:東日本大震災後の自治体の課題、災害対応改善に向けた提言
3.2.2 収集結果と課題
表1に、deep researchにより収集された市町村ごとの構造化データの一例を示す。大槌町、山田町、気仙沼市など津波被害が甚大であった沿岸部自治体では、8項目すべてにおいて詳細な情報が取得できた。一方、白石市や名取市など内陸部や津波被害が限定的であった地域でも、地震被害や原子力災害対応に関する情報が適切に抽出されている。しかし、名取市の避難人数など、不正確な数字の抽出が散見された。これは、全国の1747の自治体に対して、膨大なデータの構造化を1回のプログラム実行により行ったことによるコンテキスト過負荷に伴うハルシネーションであると考えられる。
表1 deep researchで収集された市町村ごとに構造化された災害情報の一例
| 自治体 | 岩手県大槌町 | 岩手県山田町 | 宮城県気仙沼市 | 宮城県白石市 | 宮城県名取市 |
|---|---|---|---|---|---|
| 災害概要 | 2011年3月11日、東日本大震災により大槌町は甚大な被害を受けた。 | 2011年3月11日、東日本大震災により山田町は震度5強(計測震度5.1)を観測し、津波の最大波高は約19メートルに達した。 | 2011年3月11日、宮城県気仙沼市は東日本大震災により甚大な被害を受けた。 | 2011年3月11日14時46分頃、マグニチュード9.0の東日本大震災が発生し、白石市では震度6弱を観測しました。 | 2011年3月11日14時46分、三陸沖を震源とするマグニチュード9.0の地震が発生し、名取市では震度6強を観測した。 |
| 被害状況 | 2023年7月19日時点で、死亡届受理数1,233人(身元判明者822人、行方不明者411人)、関連死52人、計1,286人が犠牲となった。 | 死者604人、行方不明者148人、家屋全壊2,762棟、大規模半壊・半壊405棟、一部損壊202棟。漁船1,791隻が流失し、養殖施設や作業小屋も壊滅的な被害を受けた。 | 気仙沼市では、死者1,143人、行方不明者214人、全壊家屋7,000棟以上が報告された。 | 市内で4名の死亡が確認され、多数の家屋や公共施設が損壊しました。 | 名取市では死者911人、行方不明者56人、重傷者14人、軽傷者191人、全壊家屋2,805棟、半壊家屋1,099棟、一部損壊家屋9,854棟の被害が発生した。 |
| 避難状況 | 震災直後、町内の避難率は52.2%で、沿岸12市町村平均の60.8%を下回った。 | 震災直後、約2,100人が避難所で生活。仮設住宅は2011年6月21日までに全戸着工し、7月20日ごろに完成予定だったが、一部で遅れが生じた。 | 震災直後、約30,000人が市内外の避難所で生活を余儀なくされた。 | 震災直後、多くの市民が避難所に避難しましたが、具体的な避難者数は不明です。 | 震災直後、名取市内の避難所には多くの住民が避難し、最大で1,323か所の避難所に320,885人が避難した。 *著者注記:本文中に記載の通り、コンテキスト過負荷に伴うハルシネーションと考えられる |
| 初動対応 | 災害対策本部の活動に関する検証報告書が作成され、役場職員の犠牲者数や初動対応の課題が明らかにされた。 | 震災発生直後、町長が防災無線で町民に避難を呼びかけ。和歌山市から職員が長期派遣され、まちづくりなどの支援を行った。 | 気仙沼市は震災発生直後に災害対策本部を設置し、自衛隊や消防、警察と連携して救助活動を展開した。 | 震災発生直後、白石市は災害対策本部を設置し、被害状況の把握や救助活動を開始しました。 | 震災直後、自衛隊や警察、消防、医療機関、全国の自治体、ボランティアなどが救助活動や支援物資の提供を行った。 |
| 長期復興計画 | 防災集団移転や土地区画整理事業が進められ、2017年12月に吉里吉里地区で200戸、町方地区で510戸の整備が完了した。 | 2011年12月22日に『山田町復興計画』を策定。10カ年の復興ステップを設定し、コンパクトなまちづくりを目指した。 | 2012年3月、気仙沼市は「気仙沼市震災復興計画」を策定し、防災集団移転や産業再生を柱とした復興を進めた。 | 2011年9月30日に『白石市東日本大震災復興計画』を策定し、2011年度から2017年度までの7年間で市民生活の再生、産業・経済の再生、防災のまちづくりを目指しました。 | 名取市は2011年10月に震災復興計画を策定し、2017年3月に改訂版を公表。計画期間は2011年度から2019年度までで、その後は第六次長期総合計画に引き継がれた。 |
| 災害医療・福祉支援 | 震災後、仮設診療所が開設され、医療体制の再構築が進められた。 | 全壊した県立山田病院は仮設診療所で再開し、2016年2月1日現在、被災施設の90.4%が再開。仮設住宅入居者は2016年1月31日現在で2万1,464人。 | 気仙沼市立病院は被災しながらも診療を継続し、全国からの医療支援チームが派遣された。 | 放射線モニタリングの強化や食品・農畜産物の放射性物質検査体制の強化など、福島第一原子力発電所事故対策を実施しました。 | 震災直後、石巻赤十字病院などの医療機関が救護班を派遣し、被災者の医療支援を行った。 |
| 教訓・減災対策 | 2022年9月21日、大槌町防災ハザードマップが全戸配布され、住民の防災意識向上が図られた。 | 『二度と津波による犠牲者を出さない』を理念に、高台移転や防潮堤の設置などの防災対策を強化。震災記録誌を発刊し、教訓を後世に伝える取り組みを行った。 | 震災の教訓を踏まえ、気仙沼市は防災教育の強化や避難訓練の定期的な実施を行っている。 | 震災の教訓を踏まえ、地域防災計画の強化や災害時情報伝達手段の確立、自主防災組織の育成などを進めました。 | 名取市は震災の記憶と教訓を後世に伝えるため、2019年に震災メモリアル公園を整備し、慰霊碑や震災遺構を設置した。 |
| 今後の課題と提言 | 震災伝承活動の推進や防災体制の強化が求められている。 | 商業機能の郊外化が進み、中心市街地の賑わいの喪失や交通弱者の買い物利便性の低下が課題。まちづくりの進展や用地確保、資金の確保が本設再開の課題として挙げられている。 | 人口減少や高齢化が進む中、持続可能な地域づくりと防災力の向上が求められている。 | 復興計画の総仕上げとして、市民生活の発展と地域経済の活性化を図るとともに、放射能対策や防災対策の継続的な強化が求められます。 | 震災から12年が経過した2023年時点でも復興は道半ばであり、住民の1割が犠牲となった閖上地区では、震災の記憶を継承し、防災・減災の重要性を伝える取り組みが求められている。 |
全体として、約8割の自治体で8項目のうち5項目以上の情報を適切に抽出できたが、以下の課題も明らかになった。
- ハルシネーションの発生: 東日本大震災で被害を受けていない地域において、存在しない被害情報が生成される例が散見された。コンテキスト過負荷に伴うハルシネーションも散見された。
- 情報の欠損: 自治体によってWebページの構造や情報公開の詳細度が異なるため、一部項目が取得できないケースがあった。
- データ品質の不均一性: 沿岸部の被災自治体は詳細な記録を公開している一方、内陸部や被害が軽微な地域では情報が限定的であった。
これらの課題に対しては、Human-in-the-loopによる検証プロセスの導入や、複数の情報源からのクロスチェック、分割したタスキングなどの対処が必要と考えられる。
3.2.3 構造化データの意義
deep researchにより構造化されたデータは、単なる情報の羅列ではなく、災害サイクルの各フェーズに対応した知識として整理されている点が重要である。知識の構造化は、災害や事故の種別に関わらず、様々な事象を整理してその因果を正確に理解し知識を再利用する上で極めて重要な考え方である[17]。これにより、ユーザーは「初動対応の事例を知りたい」「長期復興計画の策定時期を比較したい」といった目的別の検索が可能となる。また、同様の手法を他の災害(熊本地震、西日本豪雨等)に適用することで、横断的な比較分析や教訓の抽出も期待できる。
3.3 VQAによる災害画像の意味付与
3.3.1 災害判定精度の比較検証
画像が災害状況を表しているか否か、また災害の種別を正確に判定できるかを検証するため、Kaggle上で公開されている自然災害画像データセット[18]のうち、”Water_Disaster”(水害)、”Urban_Fire”(都市部火災)、”Land_Slide”(地滑り)、”Non_Damage”(被害なし)の4つに分類される画像セットを用いて、3つのVQAモデル(CLIP/BLIP/LlaVA)の精度を比較した。
表2に示す通り、「水害」、「都市部火災」、「地滑り」、「被害なし」に分類されている画像について、VQAが、対象の画像分類を適切に認識できているかを確認するためにYes/Noで質問を出し、その回答の正答率を算出した。なお表2では参考比較対象としたGPT-5の結果も併記しているが、その内容は次節で説明する。
表2から明らかなように、CLIPは「水害」の正答率が著しく低く、BLIPは「地滑り」の正答率が著しく低い。一方、LlaVAは「被害なし」の画像を災害発生ありと、誤判定するケースが少数存在した。このことから、災害分類ごとに最も高い正解率を示すモデルは異なり、CLIP・BLIP・LlaVAの間で得意分野が分かれることが確認された。
表2 災害画像の種類と各VQAによる正解率
| VQAモデル/災害分類 | 水害 | 都市部火災 | 地滑り | 被害なし |
|---|---|---|---|---|
| CLIP (0.428B) | 60% | 91% | 89% |
100% |
| BLIP (0.129B) | 81% | 98% | 67% | 100% |
| LlaVA (7B) | 89% | 90% | 80% | 96% |
| GPT-5(参考) | 94.5% |
96.8% | 82.6% | 100% |
| 画像枚数 | 1035 | 419 | 455 | 4572 |
主要な知見
- モデルごとの得意分野の差異: CLIPは「水害」の判定精度が著しく低く(60%)、BLIPは「地滑り」の判定に課題がある(67%)。一方、パラメータ数が最多のLlaVA(7B)は総合的に高い性能を示した。
- 「被害なし」画像の識別能力: いずれのモデルも災害発生時の画像と誤判定する率は低く、災害有無の判別能力は高いと評価できる。
- 軽度災害の判定困難性: 図3に示すように、CLIPが「水害」と判定できなかった画像は、人間が見ても「川のある町」なのか「洪水」なのか判別が困難なケースであった。同様に、地滑りの初期段階や小規模な崩落は専門家でなければ認識が難しく、VQAモデルも誤判定する傾向が見られた。
以上のように、今回の試行範囲においては、VQAは災害判定において一定の精度を有していると考えることができる。しかし、どの程度の規模(軽度)の災害に対して、それを災害と判定できるかという精度については、今後さらなる検証が必要である。
 図3 CLIPが水害と判断できなかった画像(左)と地滑りと判断できなかった画像(右)[18]
図3 CLIPが水害と判断できなかった画像(左)と地滑りと判断できなかった画像(右)[18]
3.3.2 GPT-5による追加検証
前節では、CLIP/BLIP/LlaVAを対象に画像分類の正答率を比較した。しかし、実際の実務利用を想定すると、判定の正否だけでなく、「なぜそう判断したか」「どの程度確からしいか」といった説明可能性や信頼性情報が意思決定においても重要になると考えられる。そこで追加検証として、商用マルチモーダルLLMであるGPT-5に対し、判定結果の根拠や信頼度を含む構造化出力の能力を評価した。
まず、画像の災害分類の正答率については、表2に示す通り、「水害」以外では必ずしも最高精度とはならなかった。しかし、GPT-5に対しては、該当する「災害分類」だけでなく、「信頼度」(0~1のスコア)、「想定ハザード」(具体的な危険要因 - 落石、浸水、倒壊等)、「判断根拠」(なぜそのように判定したか)の詳細な構造化出力をさせることで、「災害分類」の判定プロセスが明らかとなった。
図4は、GPT-5が「地滑り」と判定しなかった画像の例である。Kaggleのデータセットでは「地滑り」とラベル付けされていたが、GPT-5は表3のように判定した。
 図4 GPT-5が地滑りと判断しなかった画像の例[18]
図4 GPT-5が地滑りと判断しなかった画像の例[18]
表3 図4でGPT-5が地滑りと判断しなかった画像の特徴
| 災害分類 | 信頼度 | ハザード | 判断の理由 |
|---|---|---|---|
| なし | 0.64 | 岩場|転倒・滑落|落石の可能性 | 岩の多い渓流沿いでの活動に見え、建物被害や浸水、崩落跡などの明確な被害は確認できない。自然の地形であり災害発生を示す決定的要素が不足している。 |
| なし | 0.63 | 重機稼働|落石の恐れ|高所作業 | 作業員とクレーンがいる道路工事の様子で、倒壊・浸水・火災などの明確な被害は見当たらない。斜面補強作業にも見えるが災害直後とは断定できない。 |
| 地震 | 0.7 | 倒壊建物|瓦礫堆積|二次崩落|落下物 | 広範囲で建物が崩壊し瓦礫が密集する航空写真で、地震被害の典型的様相に近いです。原因を直接示す要素はなく津波等の可能性もあるため確信度は中程度です。 |
表3の「災害分類」は、前節で検証した3つのVQAモデルの正答率の判定で用いた「もともとのKaggleでラベル付けされていた「災害分類」を回答できるか?」ではなく、画像に対して関連付けが想定される災害種別を聞く形式とした。したがって、Kaggleではラベル付けされていない「地震」という災害分類も回答の選択肢となっている。これは、地滑りや土砂災害などの随伴事象災害など、複数の災害分類が関連付けられる可能性があることを想定したものである。
表3の結果から明らかなように、GPT-5は画像1・2を「地滑り」ではなく「自然地形」や「工事現場」と判定し、その判断根拠も論理的である。画像3については、GPT-5は、災害分類を「地震」と判定したが、もとの画像の災害分類ラベル(「地滑り」)よりもGPT-5の判断の方が妥当と考えられる結果となっている。
このように、GPT-5は単なる分類精度ではなく、判定の透明性とトレーサビリティにおいて優位性を示した。災害対応の実務では「なぜその判断をしたか」が説明できることが重要であり、この点でGPT-5のような高度なVQAモデルの価値が認められる。
3.3.3 VQA技術の災害分野への適用可能性
以上の検証から、VQAは災害画像の意味付与において以下の可能性と課題を有することが確認された。
可能性
- 明確な災害状況(大規模浸水、建物倒壊等)の判定精度は実用レベル
- 災害種別の分類が可能(モデル選択により得意分野が異なる点に注意)
- 判定根拠の構造化出力により、説明可能性を確保できる
課題
- 軽度の被害や災害の予兆段階の判定精度は不十分
- オンプレミスモデルはGPUメモリ制約により大規模モデルの利用が困難
- 商用モデルは高精度だがコストとデータガバナンスの課題
今後は、特定の災害種別に特化したファインチューニングや、複数モデルのアンサンブル手法により、精度向上の余地があると考えられる。
3.4 統合UIによる実証検証
3.4.1 プロトタイプシステムの実装
前節までに構築したデータ収集・構造化層とマルチモーダル処理層を統合し、検索・提示層を含めた、エンドユーザー向けのプロトタイプシステムを実装した。参考データとして、山口大学が構築した災害情報アーカイブデータ(Creative Commons Licenseで公開)[19]を利用した。
キャプションを持たない災害画像については、前節で検証したLlaVA (7B)を用いてVQAによるキャプショニングを実施した。RAGフレームワークにはLangChainを、LLMにはLlama2 (7B)を、実行環境にはオンプレミスのNVIDIA RTX A6000を使用した。UIは、Gradioにより作成し、ブラウザで表示されるものとした。
実装した主要機能は以下の4つである。
- 自然言語検索:
ユーザーの質問(テキスト)に対して、関連する災害情報(テキスト+画像)を返答 - 類似画像検索:
ユーザーが入力した画像に類似する過去の災害事例をデータベースから抽出 - 地図統合表示:
検索結果に該当する画像の位置情報をハザードマップ上に可視化 - 災害シナリオ生成:
平常時の画像に災害状況を合成(試験的機能)
なお、災害画像には大まかな住所情報(都道府県、市区町村レベル)が付与されているため、これを地図上にマッピングすることで、地域の災害リスクとの関連を視覚的に把握できる仕様とした。
3.4.2 動作確認結果
実装したプロトタイプシステムの動作確認結果を、機能ごとに示す。
(1) 自然言語検索機能
- 検証例:農業被害に関する情報検索
- ユーザーは、まず対象都道府県を選択し(図5)、次にチャンクサイズや最大トークン数などのパラメータを設定した上で、検索クエリを入力(図6)する。本検証では、データの一部を英語に変換しているため、質問も英語で入力した。
まず、知りたい災害情報に該当する県名を選択する。
 図5 対象都道府県の選択ダイアログ
図5 対象都道府県の選択ダイアログ
 図6 チャットによる指示(Q: 野菜への被害を教えてください)
図6 チャットによる指示(Q: 野菜への被害を教えてください)
システムは、RAGにより関連する画像とテキスト情報を検索し、以下のような回答を生成した(図7、図8)。
 図7 検索結果のテキスト出力
図7 検索結果のテキスト出力
 図8 UI上で検索結果と合わせて出力された画像[19]
図8 UI上で検索結果と合わせて出力された画像[19]
回答には、事前に構造化されたテキスト情報(台風名、日時、場所、被害内容)と、VQAが画像から生成したキャプション(図7の回答文中の赤枠部)が統合されている。VQAは事前情報を踏まえつつ、画像内容に即した説明を生成しており、適切な意味付けがなされていることが確認できる。
さらに、検索結果の位置情報(熊本県鹿本郡植木町草場)を洪水ハザードマップ(国土数値情報・洪水浸水想定区域図)上に重ねてプロットすると、図9のように該当地域は洪水リスクの高いエリアであることが判明した。これにより、ユーザーは強風被害だけでなく、複合的な災害リスクも把握できる。
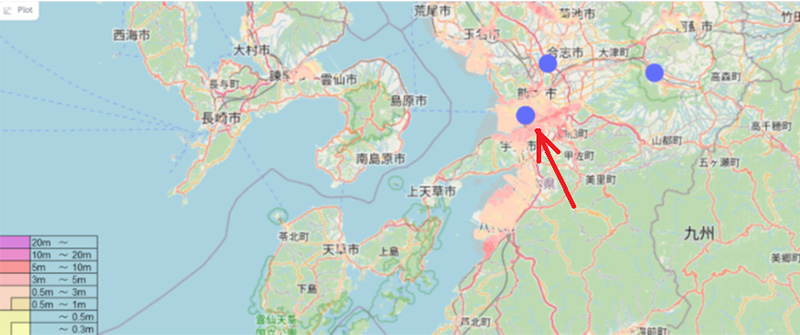 図9 検索結果に該当する位置情報の洪水ハザードマップ上の可視化
図9 検索結果に該当する位置情報の洪水ハザードマップ上の可視化
-
※青丸は、図6の質問に対する回答で出力された災害事例の位置の一部を示す。
矢印は、本例(図7,8)の熊本県鹿本郡植木町草場の位置を示す。
背景地図:© Mapbox, © OpenStreetMap contributors(ODbL)
洪水浸水想定区域図(ラスタ):国土地理院「ハザードマップポータルサイト」
(2) テキストによる類似画像検索
次に、テキスト入力から類似画像を検索する機能を検証した。「道路上の被害」というキーワードを入力すると、システムはVectorDBから関連度の高い画像を抽出し、VQAが生成した説明文とともに表示した(図10)。
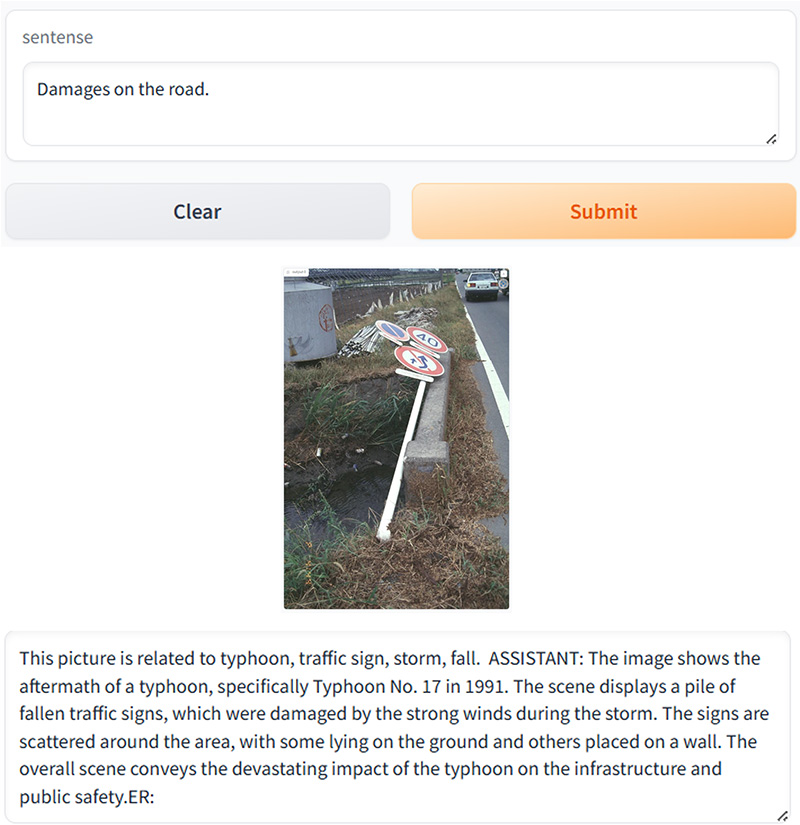 図10 テキストにより検索された画像[19]とそのVQA説明による説明文
図10 テキストにより検索された画像[19]とそのVQA説明による説明文
VQAの説明では「倒れた交通標識」と記述されているが、画像のみからは道路上の物体が実際に交通標識であるか否かを人間が判断することも困難である。しかし、質問(道路上の被害)に対する回答としては妥当な内容であり、ユーザーに関連事例を提示する目的は達成されていると評価できる。
(3) 画像による類似画像検索
ユーザーが特定の災害現場を撮影した際に、過去の類似事例を検索できる機能を検証した。図11左の画像(河川増水と住宅地)を入力すると、システムはデータベースから類似度の高い上位4枚を抽出した(図11右)。
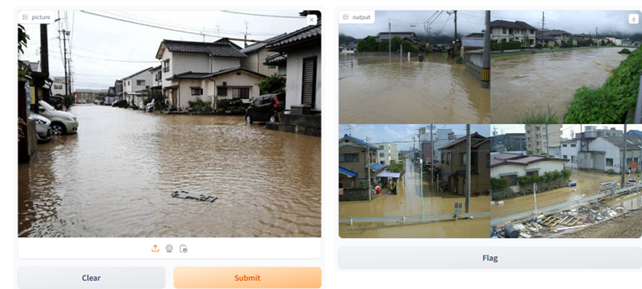 図11 入力画像(左)とその類似画像の上位4枚の出力(右) [19]
図11 入力画像(左)とその類似画像の上位4枚の出力(右) [19]
視覚的に、入力画像と検索結果は増水の様子や住宅地の配置が類似しており、適切な検索が行われたと判断できる。この機能により、ユーザーは現在直面している状況と類似した過去事例を参照し、被害の進行予測や対応策の検討に活用できる。
3.4.3 実装上の課題
プロトタイプシステムの動作検証を通じて、以下の技術的課題が明らかになった。
- 応答速度: LlaVA (7B) + Llama2 (7B) + RAGの組み合わせでは、1クエリあたり5~10秒の応答時間を要した。実災害時の迅速な情報提供には、さらなる高速化が必要である。
- GPUメモリ制約: 48GBのVRAMでは、13B以上のパラメータを持つモデルの実行が困難であった。より高性能なモデル(LlaVA 34B等)の利用には、ハードウェアの増強が必要となる。
- ハルシネーション: RAG検索で関連性が低い情報が混入した場合や、VQAが画像を誤認識した場合に、事実に基づかない回答が生成されるケースが散見された。
- UI操作性とユーザビリティ: 現状のUIは技術検証を目的としたものであり、実用化に向けては、ユーザー属性に応じたUI/UXの設計が不可欠である。
試行を通じた知見のまとめ
本章では、地域特化型災害ナレッジベースの構築に向けて、データ収集の自動化(deep research)、画像の意味付与(VQA)、統合検索システム(RAG + LLM + UI)の3つの要素技術を実装し、その可能性と課題を検証した。内容と課題を表4に示す。
表4 各試行項目の内容と課題
| 試行項目 | 内容 | 課題 |
|---|---|---|
deep researchによる構造化 |
|
|
VQAによる画像判定 |
|
|
統合UIでの検索・可視化 |
|
|
重要な示唆
本章の試行から、以下の3点が重要な示唆として得られた。
1. RAG + VQAの技術的実現可能性
散在する災害情報(自治体Web、画像アーカイブ等)を、RAGとVQAの組み合わせにより統合的に検索可能とする技術的実現性を確認した。これにより、従来は個別に管理されていた文書情報と画像情報を横断的に扱い、地域固有の災害知識を効率的に参照できる基盤が構築できる。
2. オンプレミス実装の可能性と限界
7Bパラメータのモデル(LlaVA、Llama2)でも、基本的な災害情報検索には実用レベルの性能を達成した。これにより、データガバナンスやプライバシー保護が求められる組織でも、外部APIに依存せず独自の災害ナレッジベースを構築できる可能性が示された。
一方、GPT-5等の商用モデルと比較すると、精度・機能面(特に判定根拠の説明能力)では劣る。コストと性能、データガバナンスのトレードオフを考慮した選択が必要である。
3. ユースケースに応じた精度・機能要件の重要性
本試行は技術的可能性の検証を目的としたものであるが、実用化に向けては「誰が」「何のために」使うのか(例えば、以下)を明確にし、それに応じた精度・機能要件を定義する必要がある。
- 防災教育: 精度だけでなく直感的な理解も重要。画像生成やVR連携なども視野。
- 企業BCP策定: 過去事例の参照と類似検索。個別性への対応が鍵。
- 緊急対応: 即時性と高精度/高説明性が必須。ハルシネーションは許容できない。
以上の観点は、技術的な改善だけでは解決できず、災害科学や認知科学、防災実務の専門知見を統合した検討が不可欠である。
次章では、東北大学災害科学国際研究所の各分野の専門家との意見交換を通じて、社会実装に向けた多角的な考察を行う。本章で確認された技術的可能性を、実際の防災・減災の現場でどのように活用できるか、また何が課題となるかについて、より広範な視点から議論する。
4. 外部有識者との意見交換と技術実装への示唆
災害情報の高度な活用プラットフォーム構築に向けた検討の一環として、2024年度に東北大学災害科学国際研究所(IRIDeS)の有識者と学術指導契約を締結し、計3回にわたる意見交換会を実施した。本章では、同研究所の専門家との議論を通じて得られた、生成AI・マルチモーダルAIの防災適用における課題と解決の方向性を整理する。
なお、本取り組みは特定の研究成果を報告するものではなく、生成AI・マルチモーダルAIの防災活用について、学術的見地からの多角的な検証と知見の獲得を目的としたものである。そのため、発言者を特定せず、議論のエッセンスを抽出して記述する。また、議論の中で共有された観点を著者にて“示唆”として整理したものであり、個々の発言者の見解を代表するものではない点に注意されたい。
4.1 意見交換会の全体像
意見交換は、災害対応プロセスを「認知」「周知」「対応」の3つのフェーズに体系化し、各回で主要なテーマを設定しつつ自由な意見交換の形式で実施した。
- 第1回(2024/7/17):
認知:物理的ハザードとAI技術基盤- 災害科学の専門知識とデータ資産
- マルチモーダルAIの技術的可能性
- ターゲットユーザーとユースケース
- 第2回(2024/10/16):
周知:人間の認知・判断・伝承- 災害時の人間の意思決定メカニズム
- 知識の伝承と教育の効果
- LLM/RAGの活用方法(適用可能性と限界)
- 第3回(2025/1/22):
対応:実用化に向けた課題と責任- データの信頼性の重要性
- 個別性と汎用性
- ユースケースに応じた正確性/精度
なお、意見交換を具体的なものとするために、著者より、マルチモーダルAIを活用した試行事例を説明した。具体的には、前章で説明をした一部の取組を中心に、災害アーカイブ写真を用いたAIによる自動キャプショニングの試行を紹介し、地域特化のマルチモーダルな災害情報を集約したVectorDBを構築し、RAGを介して汎用LLMがユーザーの質問に正確に応答する、地域特化型災害ナレッジベースへの活用可能性を説明した。
4.2 認知フェーズに関する示唆
第1回では、災害発生時の状況把握への活用可能性について議論がなされた。生成AIやマルチモーダルAIは、画像・音響・センサーデータ等の異種情報を統合処理できる点が利点となるが、防災実務への適用などの観点で、データの文脈適合を見据えた育成型AIや、複雑系を前提とした“差分の検出”などの意見が示された。
- 一般的なLLMでは地域特性が反映されにくく、固有の環境や設備データを継続的に取り込む“育成型AI”の有効性が議論された。
- 災害の多くは複雑系であり、状態そのものを予測するよりも、平常時との差分(アノマリー)を検出するアプローチが現実的であるとの認識が共有された。
- PINNs(Physics-Informed Neural Networks)等のデータ同化技術により、観測データを踏まえたリアルタイム更新が可能となる一方、計算負荷やデータ整備の課題が指摘された。
4.3 周知フェーズに関する示唆
第2回では、情報の「受け手」である人間の認知・心理特性に焦点が当てられた。認知科学・伝承・教育の専門家を中心に、身体性や体験の重要性や、具体⇔抽象の往復による記憶定着、ユーザーやユースケースに応じたUI/UXや信頼性や精度の重要性について示された。
また、メタ認知や、記憶と忘却、身体性やグランディングといったLLMが持つ言語理解の限界や本質に迫る議論もなされた。
- 文章理解や記憶定着には、既有知識の活性化や具体⇄抽象の往復が重要であることが紹介され、AIが情報の再構成や提示方法を工夫する余地があることが示唆された。
- 伝承研究からは、生身の語り部の効果や、体験的要素を含む学習の重要性が示された。AIによるVR・物語生成などの補助的活用が期待される。
- 行政向け、企業向け、市民向けでは必要とされる精度・出典・説明形式が異なるため、利用者属性に応じたUI/UX設計が不可欠である。
4.4 対応フェーズに関する示唆
第3回では、実災害における対応と復旧・復興支援や、災害関連死を含めた災害医療現場など、実務的なオペレーションでの可能性や課題について議論がなされた。個別性への対応や、責任の所在、人間とAIの役割など、AI利用に係る本質的なテーマにまで議論がおよんだ。
- 企業や組織のBCPは拠点ごとの個別性が極めて高く、学習データの量や質に起因して、AIが包括的に精度の高い情報を出力することは難しい一方、リソース特定や類似事例の整理などタスクを限定すれば有用性が高いのではないか。
- 生成情報の責任問題やデータの信頼性確保について指摘があり、検証済みデータの活用やデータの構造化には特に注意が必要である。
- あらゆる災害事象を網羅しようとする「オールハザード」型のアプローチは、シナリオが複雑化し破綻しやすいが、災害原因問わず、利用可能なリソース状態に着目して復旧戦略を立てる「マルチハザード(リソースベース)」のアプローチがAI実装に適しているのではないか。
- ハルシネーションをゼロにできない以上、意思決定プロセスには必ず専門家や担当者の確認工程(Human-in-the-loop)を組み込み、AIはあくまで人間の判断を拡張・支援する存在と定義すべきではないか。
4.5 総括
一連の議論を通じて、マルチモーダルAIの利活用や研究開発の方向性について、以下の方向性が導き出せた。
- 階層的なデータ戦略(Data Strategy):
AIシステムを「一般知識層」「専門知識層」「地域・文脈特化層」の階層構造で設計することで、組織や利用主体の文脈依存性や、地域依存性といった固有性を反映した「個別解」の精度を高める必要性。 - 人間中心の設計(Human-Centric Design):
技術や正確性の観点だけではなく、人間の認知バイアス(正常性バイアスなど)や心理的特性を考慮したUI/UXによるユーザーの「行動変容」の観点の重要性。 - 信頼性の担保と責任分界(Trust & Accountability):
出典明示やトレーサビリティの徹底、人間とAIの役割分担、ユースケースに応じた目標精度の追求、などを踏まえ、信頼性の高いデータを起点に、限定的な領域で実証しながら拡大するアプローチ
 図12 意見交換会の様子
図12 意見交換会の様子
表5 意見交換会に参加いただいた各分野の専門家
-
注記)所属は2025年9月時点。研究キーワードは、東北大学HPより
| 氏名 | 参加会 | 所属 | 専門領域/研究キーワード |
|---|---|---|---|
| 今村文彦 | 1,2,3 | 東北大学災害科学国際研究所 教授 | 津波工学 / 自然災害科学 |
| 鎌田健一 | 1,2,3 | 東北大学災害科学国際研究所 特任教授 | 防災ISO / 防災教育 |
| 森口周二 | 1 | 東北大学災害科学国際研究所 准教授 | 斜面災害 / 地盤災害 / 数値解析 / 災害調査 |
| 柴山明寛 | 1 | 東北大学災害科学国際研究所 准教授 | 震災アーカイブ / 災害教訓 / メタデータ / AI / 地震工学 |
| サッパシー・アナワット | 1 | 東北大学災害科学国際研究所 准教授 | 海岸工学 / 津波ハザード・リスク評価 / 津波防災対策 / 連鎖災害 / 世界津波の日 |
| 杉浦元亮 | 2 | 東北大学災害科学国際研究所 准教授 | 認知神経科学 / 脳科学 / 認知科学 / 実験心理学 |
| 佐藤翔輔 | 2 | 東北大学災害科学国際研究所 准教授 | 災害伝承学 / 災害情報学 / 災害文化 / 情報処理過程 / 避難行動 |
| 邑本俊亮 | 2 | 東北大学災害科学国際研究所 教授 | 認知心理学 / 教育心理学 / 文章理解 / 授業デザイン / 防災教育 |
| 乾健太郎 | 2 | 東北大学大学院情報科学研究科 教授 | 自然言語処理 / 人工知能 |
| 丸谷浩明 | 1,2,3 | 東北大学災害科学国際研究所 教授 | 事業継続マネジメント(BCM) / 企業防災 / 防災計画 / 防災法制 / 防災ボランティア |
| 江川新一 | 1,3 | 東北大学災害科学国際研究所 教授 | 災害医療 / 医療ニーズ / 国際協力 / シミュレーション / 東日本大震災 |
| 奥村 誠 | 1,2,3 | 東北大学災害科学国際研究所 教授 | 避難計画 / 防災計画 / 災害影響分析 / 最適化 |
5. まとめと今後の展望
本稿では、散在する災害情報を「テキスト+画像+位置情報」として統合し、deep research による収集・構造化、VQA による画像キャプショニング、RAG+LLM による検索・提示を組み合わせた地域特化型災害ナレッジベースの技術的実現可能性を示した。
試行の結果、VQA+RAG+LLMによるハルシネーションの少ない地域特化型災害ナレッジベースの可能性を展望できた一方、データの品質不均一性や入手可能性、ユースケースに応じた信頼性の確保やUI/UX設計が実用化の主要課題として整理された。
生成AIの進化は今後も続く中で、既存のアーカイブ情報の構造化やメタデータ付与などで、生成AIの活用余地は大いにあると考えられる。固有性の強い災害事象において、地域の災害記録誌や災害伝承、画像記録などについてマルチモーダルAIを利用して再利用可能な形で構造化し、既存の体系知も加味することで、地域特化型災害ナレッジベースの構築が現実のものとなり、既存の汎用LLMと組み合せても、防災教育やリテラシー向上といった目的に耐えうる精度と信頼性を有する回答を得ることが期待される。
今後は、具体的な災害アーカイブデータをもちいたメタデータの付与や構造化を進め、実務現場での評価と改善を試行し、適用可能性検証を実施していく予定である。
参考文献
-
[1]内閣府: 新総合防災情報システム(参照日2025/12/19)
-
[2]デジタル庁: 災害派遣デジタル支援チーム(D-CERT)の体制強化(参照日2025/12/19)
-
[3]戦略的イノベーション創造プログラム:スマート防災ネットワークの構築(参照日2025/12/19)
-
[4]岩澤 諄一郎、大野 健太:「日本語医療大規模言語モデルの進展と課題」、人工知能40巻5号、pp.726-734、2025
-
[5]国立国会図書館: 東日本大震災アーカイブ ひなぎく(参照日2025/12/19)
-
[6]東北大学災害科学国際研究所: みちのく震録伝(参照日2025/12/19)
-
[7]Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, [Preprint].arXiv. arXiv:2005.11401v4 [cs.CL], 2020
-
[8]佐藤一郎、矢野良輔、今村文彦:「マルチモーダルAIの災害分野活用の一考察(その1)」、日本建築学会大会 学術講演梗概集(情報システム技術)、2025年7月
-
[9]Z. Lei, et al., “Harnessing Large Language Models for Disaster Management: A Survey”, [Preprint].arXiv. arXiv:2501.06932v2 [cs.CL], 2025
-
[10]A. Radford, et al., “Learning Transferable Visual Models From Natural Language Supervision”, [Preprint].arXiv. arXiv:2103.00020v1 [cs.CV], 2021
-
[11]J. Li, et al., “BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation”, [Preprint].arXiv. arXiv:2201.12086v2 [cs.CV], 2022
-
[12]H. Liu, et al., “Visual Instruction Tuning”, [Preprint].arXiv. arXiv:2304.08485v2 [cs.CV], 2023
-
[13]A. Awadalla et al., “OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models”, [Preprint].arXiv. arXiv:2308.01390v2 [cs.CV], 2023
-
[14]A. Sarkar and M. Rahnemoonfar, “RESCUENet-VQA: A Large-Scale Visual Question Answering Benchmark for Damage Assessment”, IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 2023
-
[15]市川 佑馬、矢野 良輔:「大規模マルチモーダルAIの数理と災害分野への応用」、 東京大学数理科学研究科 数理科学実践研究レター、2024
-
[16]矢野良輔、佐藤一郎、今村文彦:「マルチモーダルAIの災害分野活用の一考察(その2)」、日本建築学会大会 学術講演梗概集(情報システム技術)、2025年7月
-
[17]田村 泰彦:「SSMによる構造化知識マネジメント: 設計開発における不具合防止に役立つ知識の構築と活用」、日科技連、2012
-
[18]Arpit Verma, “Disaster Images Dataset”, Kaggle(参照日2025/12/19)
-
[19]山口大学:気象災害画像データベース(参照日2025/12/19)
コンサルタント紹介
東京海上ディーアールでは、様々な業界に精通した経験豊富なコンサルタントが課題解決のお手伝いをします。
東京海上ディーアールへのお問い合わせはこちらからお問い合わせください。
WEBからのお問い合わせ
お電話からのお問い合わせ
(ビジネスリスク本部)